決策樹算法是最簡單但功能強大的監督機器學習演算法之一。決策樹算法可用於解決機器學習中的回歸和分類問題。這就是為什麼它也被稱為CART或分類(Classification)和回歸(Regression )樹。顧名思義,在決策樹中,我們形成了一個樹狀的決策模型及其可能的結果。
以下是在Data Science視頻中查看Intellipaat決策樹:
https://www.youtube.com/watch?v=3oU7-Lv1R1U
在我們深入了解這個有趣的算法之前,讓我們來看看這個blog提供的概念。
- Decision Tree Algorithm Example
- Types of Decision Tree Algorithms
- Terminologies related to Decision Tree Algorithms
- Advantages of Decision Tree Algorithms
- Disadvantage of Decision Tree Algorithms
- How Does a Decision Tree in Machine Learning Work?
- Decision Tree in Machine Learning: Decision Tree Classifier and Decision Tree Regressor
- Creating and Visualizing a Decision Tree Regression Model in Machine Learning Using Python
接下來讓我們開始進入主題吧!
決策樹演算法範例
莫妮卡的堂兄瑪麗本週末將訪問中央公園。現在,莫妮卡需要為周末制定一些計劃,無論是出去購物,去看電影,在中央公園咖啡館消磨時光,還是只是呆在一起玩棋盤遊戲。她決定創建一個決策樹,讓事情變得簡單。讓我們看看她創造了什麼。
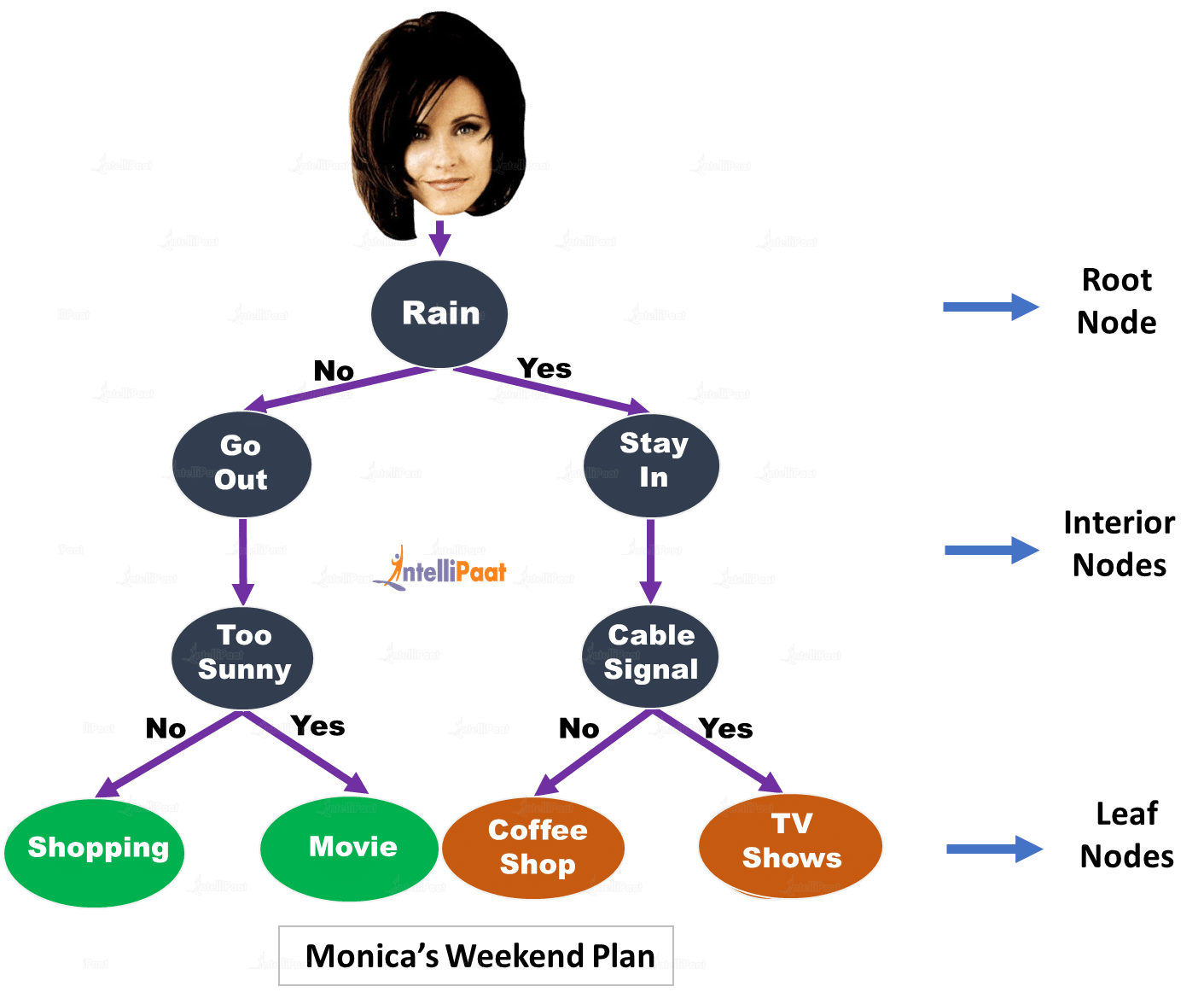
內部節點(interior nodes)表示對屬性(attribute)的不同測試(例如,是否出去或留在),分支(branches)保存那些測試的結果,葉節點(leaf nodes)表示類別標籤(class label)或在測量所有屬性後做出的某些決定。從根節點到葉節點的每條路徑表示決策樹分類規則。
規則1:如果不下雨而不是太陽光,那就出去購物吧。
規則2:如果外面不下雨但外面太陽光,那就去看電影吧。
規則3:如果在外面下雨並且電纜有信號,那麼觀看電視節目。
規則4:如果下雨並且電纜信號失效,那麼花時間在樓下的咖啡店
這就是決策樹如何幫助Monica與她的堂兄一起制定完美的周末計劃。
決策樹演算法的類型
有兩種類型的決策樹。它們根據它們具有的目標變量(target variable)的類型進行分類。如果決策樹具有分類目標變量,則將其稱為“分類變量決策樹”(categorical variable decision tree)。同樣,如果它有一個連續的目標變量,它被稱為“連續變量決策樹”(continuous variable decision tree)。
與決策樹演算法相關的術語
根節點(Root Node):此節點分為不同的同類(homogeneous )節點。它代表整個樣本。
拆分(Splitting):將節點拆分為兩個或多個子節點(sub-nodes)的過程。
內部節點(Interior Nodes):它們代表屬性的不同測試。
分支機構(Branches):他們持有這些測試的結果。
葉子節點(Leaf Nodes):當節點不能進一步分割時,它們被稱為葉子節點。
父節點和子節點(Parent and Child Nodes):創建子節點的節點稱為父節點。並且,子節點稱為子節點。
決策樹演算法的優點
- 容易明白
- 需要最少的數據清理
- 對數據類型沒有約束
以下是在Data Science視頻中查看Intellipaat決策樹:
https://www.youtube.com/watch?v=4gqZLajDWh8
決策樹演算法的缺點
- 過度擬合(overfitting)的可能性
機器學習中的決策樹如何作業?
下面給出了使用機器學習中的決策樹訓練和預測目標特徵(target features)的過程:
- 使用一組特徵和目標來提供包含許多訓練實例(instances)的數據集
- 在DecisionTreeClassifier()或DecisionTreeRegressor()方法的幫助下訓練決策樹分類或回歸模型,並在構建決策樹模型時添加所需的標準
- 使用Graphviz可視化決策樹模型
如此而已! 您的決策樹模型已準備就緒。
機器學習中的決策樹-DecisionTreeClassifier()和DecisionTreeRegressor()
DecisionTreeClassifier():它只是決策樹分類器函數,在使用Python的機器學習中構建決策樹模型。 DecisionTreeClassifier()函數如下所示:
DecisionTreeClassifier (criterion = ‘gini’, random_state = None, max_depth = None, min_samples_leaf =1)
以下是一些重要參數:
- criterion:用於衡量決策樹分類中的分割質量。默認情況下,它是'gini';它還支持'熵'(entropy)。
- max_depth: 用於在擴展樹後為決策樹添加最大深度。
- min_samples_leaf: 此參數用於添加在葉節點處出現所需的最小樣本數。
DecisionTreeRegressio():決策樹回歸函數用於在機器學習中使用Python構建決策樹模型。DecisionTreeRegressor()函數如下所示:
DecisionTreeRegressor (criterion = ‘mse’, random_state =None , max_depth=None, min_samples_leaf=1,)
- criterion:此函數用於測量決策樹回歸中的分割質量。 默認情況下,它是'mse'(均方誤差),它還支持'mae'(平均絕對誤差)。
- max_depth: 用於在擴展樹後為決策樹添加最大深度。
- min_samples_leaf: 此參數用於添加在葉節點處出現所需的最小樣本數。
利用Python在機器學習中創建和可視化決策樹回歸模型
問題陳述:使用機器學習根據一些經濟因素預測房屋的售價。 使用Python中的決策樹構建模型。
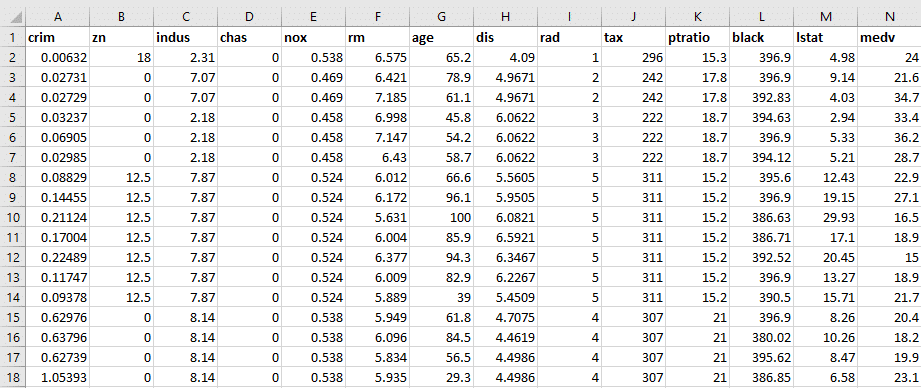
數據集:波士頓住房數據集
讓我們快速瀏覽一下數據集:
建構模型
讓我們在Python中構建決策樹的回歸模型。
步驟1:加載所需的包

步驟2:加載Boston數據集
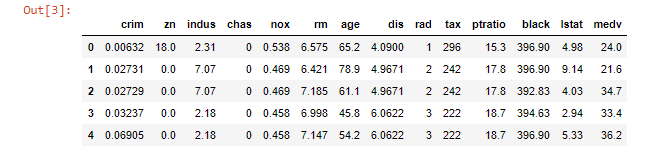
看一下數據集的前五項
步驟3:使用散點圖可視化數據集

步驟4:定義功能和目標

步驟5:將數據集拆分為訓練集和測試集

執行此步驟後,'clf_tree.dot'文件將保存在您的系統中。 現在可視化樹,使用“.dot”擴展名打開此文件並複制graphviz數據。 然後,轉到網站“http://www.webgraphviz.com/”並在其中粘貼graphviz數據,如下所示:

點擊‘Generate Graph’
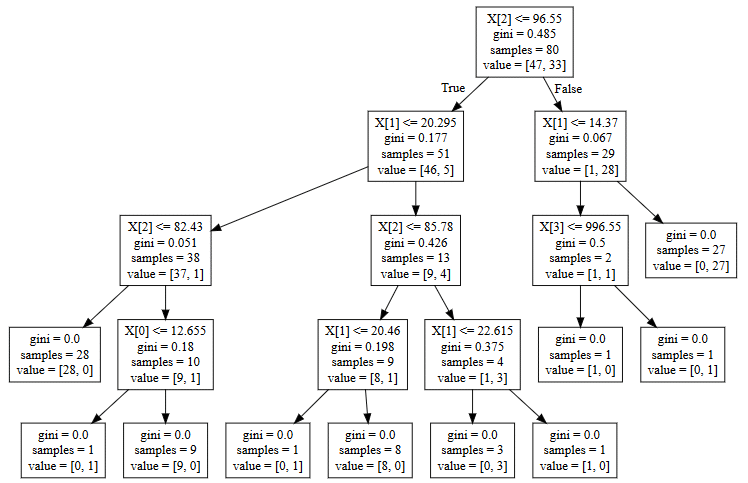
完成此步驟後,現在讓我們執行決策樹分析。
步驟7:預測值
步驟8:比較y_test和y_pred


步驟9:找到該決策樹分類模型的混淆矩陣(confusion matrix)和其他度量(metric )參數

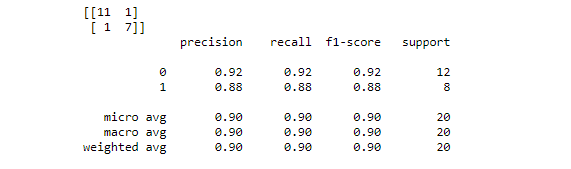
我們到底學到了什麼?
在這個決策樹教程blog中,我們回答了“什麼是決策樹演算法?”的問題。我們還學習瞭如何在決策樹分類器和決策樹回歸器,決策樹分析以及決策樹的幫助下構建決策樹分類模型。 使用Python,Scikit-Learn和Graphviz工具在機器學習中進行演算法可視化。
參考
https://intellipaat.com/blog/decision-tree-algorithm-in-machine-learning/
沒有留言:
張貼留言