循環神經網絡是第一種同類最先進的演算法,當給出大量的序列數據時,它能夠記憶/記住之前的輸入在記憶體中。
Why Not Neural Networks/Feed forward Networks?
訓練有素的前饋神經網絡可以看見任何巨大的隨機圖像集合,並被要求預測輸出。
在這個訓練過程中,神經網絡看見第一張圖片不一定會改變它對第二張圖片進行分類的方式。
這裡Cat的輸出與輸出Dog無關。 有幾個情況,理解先前的數據很重要。例如:閱讀書籍,理解歌詞,... 這些網絡沒有記憶,無法理解閱讀書籍等序列數據。
我們如何克服理解先前輸出的挑戰?
解決方案:RNN。
What are RNN’s?
RNN背後的想法是利用序列資訊。 在傳統的神經網絡中,我們假設所有輸入(和輸出)彼此獨立。 但對於許多任務而言,這是一個非常糟糕的想法。 如果你想預測句子中的下一個單詞,你最好知道它前面有哪些單詞。 RNN被稱為循環,因為它們對序列的每個元素執行相同的任務,輸出取決於先前的計算,並且您已經知道它們具有“記憶”,其擷取有關目前已計算內容的資訊。
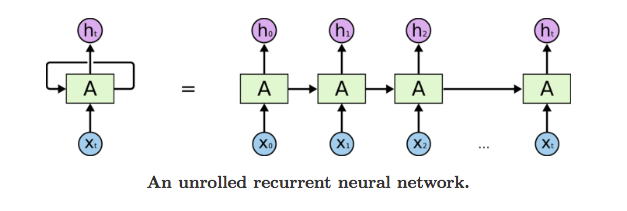
“只要存在一序列數據,並且連接數據的時間動態比每個單獨框架的空間內容更重要。”
- Lex Fridman(麻省理工學院)
有關RNN的更多資訊,請參閱下文。
Different types of RNN’s
循環網絡更令人興奮的核心原因是它們允許我們對向量序列進行操作:輸入,輸出或最常見情況下的序列。 一些例子可能會使這更具體:

上圖中的每個矩形表示向量,箭頭表示函數。 輸入向量為紅色,輸出向量為藍色,綠色表示RNN的狀態。
One-to-one:
這也稱為Plain/Vaniall Neural networks。 它處理固定大小的輸入到固定大小的輸出,它們與先前的資訊/輸出無關。
例如:圖像分類。
One-to-Many:
它將固定大小的資訊作為輸入處理,將數據序列作為輸出。
例如:圖像字幕將圖像作為輸入並輸出單詞的句子。
Many-to-One:
它將序列資訊作為輸入並輸出固定大小的輸出。
例如:情感分析,其中給定的句子被分類為表達正面或負面情緒。
Many-to-Many:
它將一系列信息作為輸入並處理它循環輸出序列數據。
例如:機器翻譯,RNN用英語讀取一個句子,然後用法語輸出一個句子。
Bidirectional Many-to-Many:
同步序列輸入和輸出。 請注意,在每種情況下,長度序列都沒有預先特別限制,因為循環變換(綠色)是固定的,並且可以根據需要應用很多次。
例如:視頻分類,其中我們希望標記視頻的每個框架。
CNN vs RNN:
我不認為你需要解釋這個。 查看下圖,您可以輕鬆獲得它:

Deep view into RNN’s:
在簡單的神經網絡中,您可以看到輸入單元,隱藏單元和輸出單元,它們獨立地處理與前一個無關的資訊,並且我們給隱藏的單位賦予了不同的權重和偏差,沒有機會記住任何資訊。

RNN中的隱藏層具有相同的權重和偏差,並在整個過程中使他們有機會記住通過它們的資訊。

Current time stamp:
看看上圖,其中當前狀態的公式為:

其中Ot是輸出狀態,ht→當前時間標記(time stamp),ht-1→是前一個時間標記,xt被傳遞作為輸入狀態。
Applying activation function:

W是權重,h是單個隱藏向量,Whh是先前隱藏狀態下的權重,Whx是當前輸入狀態下的權重。
其中tanh是激活函數,它實現非線性,將激活壓縮到範圍[-1.1]
Output:

Yt是輸出狀態。 為什麼權重處於輸出狀態。
範例:“字元級語言模型”在下面說明。
Character level language model:
我們將給RNN一大塊文本,並給定一先前字元序列要求它對下一個字元序列中的機率分佈進行建模。

作為一個工作範例,假設我們只有四個可能的字母“helo”的詞彙,並且想要在訓練序列“hello”上訓練RNN。 這個訓練序列實際上是4個獨立訓練範例的來源:
1. “e”的概率應該可能被“h”的上下文賦予
2. “l”應該可能在“he”的上下文
3. “l”也應該被“hel”的上下文賦予
4. “o”應該可能被“hell”的上下文賦予
你可以在這裡和這裡得到更多關於這個例子。
Backpropogate Through Time:
為了理解和可視化Backpropogation,我們可以在所有時間標記上展開網絡,以便您可以看到權重如何更新。返回每個時間標記來更改/更新權重稱為Backpropogate through time。

我們通常將完整序列(單詞)視為一個訓練範例,因此總誤差只是每個時間步(字元)的誤差之和。 我們可以看到的權重在每個時間步都是相同的。 讓我們總結一下時間反向傳播的步驟
1.首先使用當下輸出和實際輸出計算交叉熵誤差
2.請記住,網絡已針對所有時間步驟展開
3.對於展開的網絡,針對權重參數計算每個時間步長的梯度
4.現在,對於所有時間步長情況下,權重是相同的,可以將梯度組合在一起用於所有時間步長
5.然後更新循環神經元和綢密層(dense layers)的權重
注意:回到每個時間標記並更新其權重實際上是一個緩慢的過程。 它需要計算能力和時間。
在Backpropogating的同時,您可能會遇到兩類問題。
(i)消失的梯度 (Vanishing Gradient)
(ii)爆炸的梯度 (Vanishing Gradient)
Vanishing Gradient:
在梯度下降步驟中,早期步驟的貢獻變得無關緊要。
當您使用Backpropogating through time時,您會發現Error是Actual和Predicted模型的區別。 現在,如果關於重量的誤差的偏導數非常小於1,該怎麼辦?

如果Error的偏導數小於1,那麼當它與Learning rate相乘時也會非常小。 然後,與前一次迭代相比,Learning rate乘以誤差的偏導數不會是一個很大的變化。
例如:假設值下降0.863→0.532→0.356→0.192→0.117→0.086→0.023→0.019 ..
你可以看到最後3次迭代沒有太大的變化。 這種被稱為消失的梯度。

另外,這種消失的梯度問題導致在訓練期間忽略長期依賴性。
你可以在這裡即時想像這個消失的梯度問題。
多年來已經提出了幾種消除梯度問題的解決方案。 最受歡迎的是前面提到的LSTM和GRU單元,但這仍然是一個活躍的研究領域。
Exploding Gradient:
當演算法為權重賦予愚蠢的高重要性時,我們可以說是爆炸梯度。 但幸運的是,如果你截斷或擠壓漸變,這個問題很容易解決。
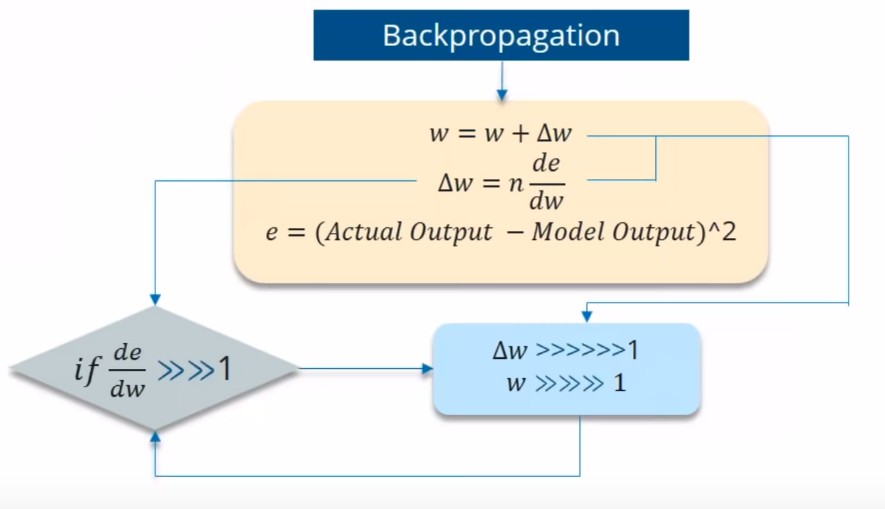
同樣在這裡,如果Errror的偏導數超過1怎麼辦?
你怎麼能克服消失和爆炸的梯度?
消失的梯度可以被克服
(i)Relu激活函數。
(ii)LSTM,GRU。
爆炸的梯度可以被克服
(i)截斷BTT(而不是在最後一個時間標記上啟動backprop,我們可以選擇類似的時間標記之前。)
(ii)將梯度降低到閾值。
(iii)RMSprop調整學習率。
Advantages of Recurrent Neural Network
1. RNN相對於ANN的主要優點是RNN可以對數據序列(即時間序列)進行建模,以便可以假設每個樣本都依賴於先前的樣本。
2. 循環神經網絡甚至與卷積層一起使用以擴展有效像素鄰域。
Disadvantages of Recurrent Neural Network
1.梯度消失和爆炸問題。
2.訓練RNN是一項非常困難的任務。
3.如果使用tanh或relu作為激活函數,它不能處理很長的序列。
Long Short Term Memory:
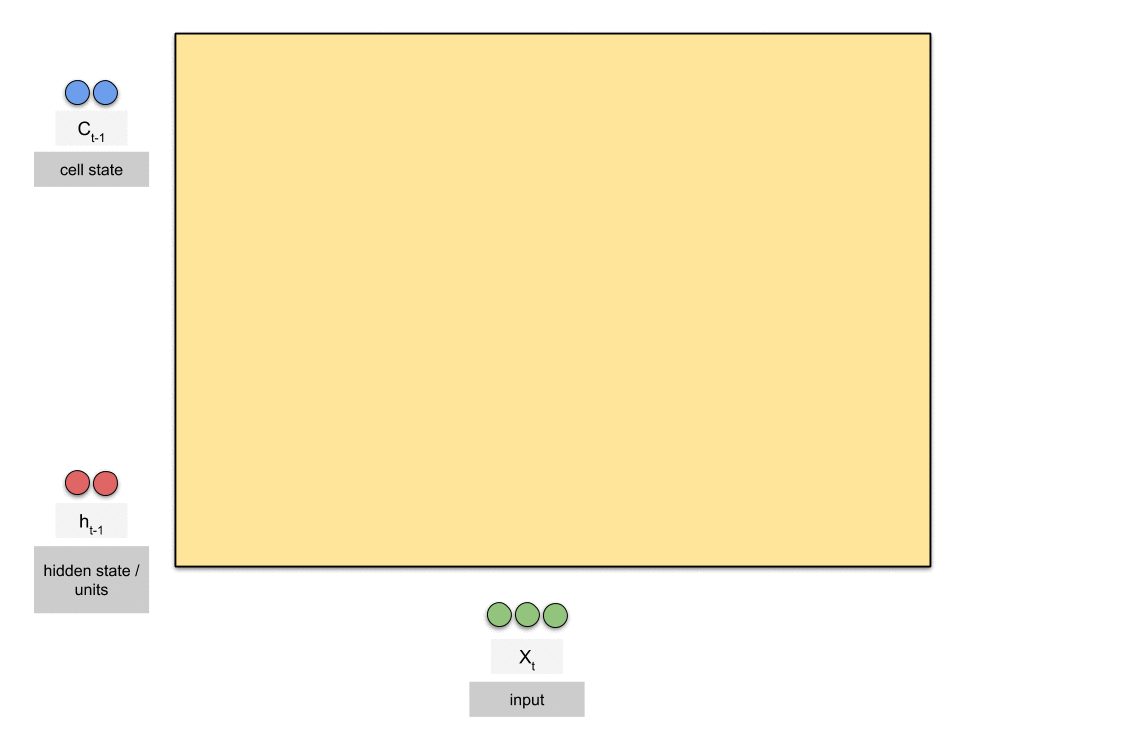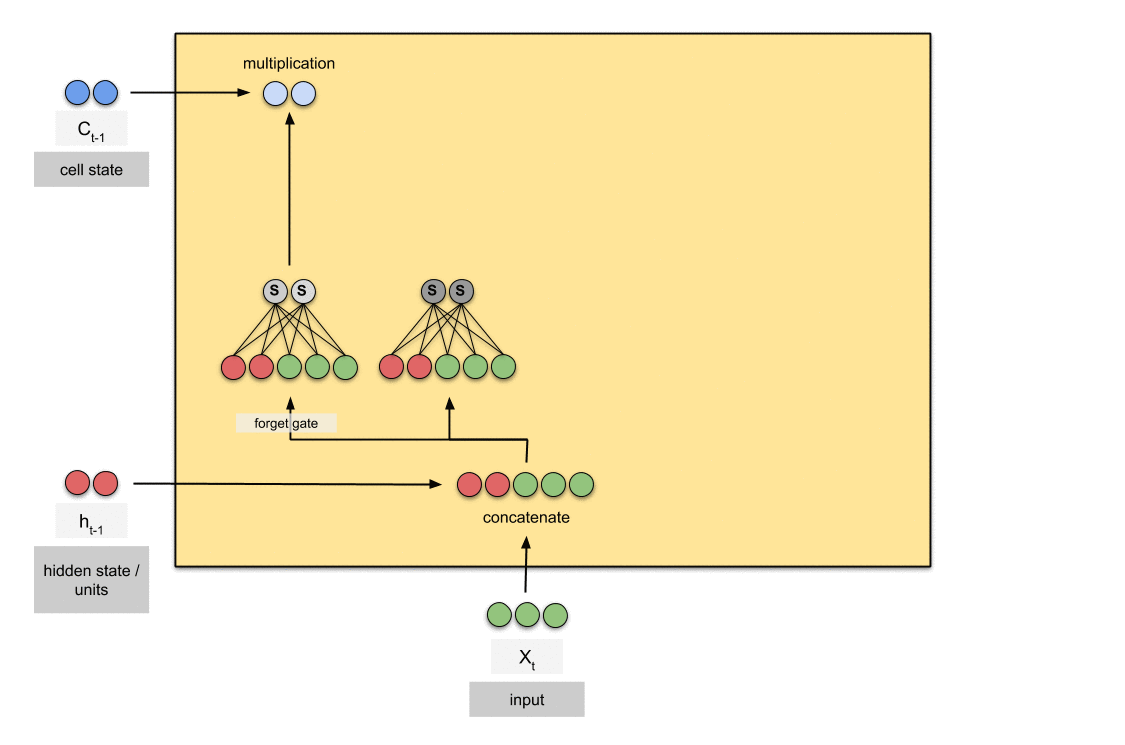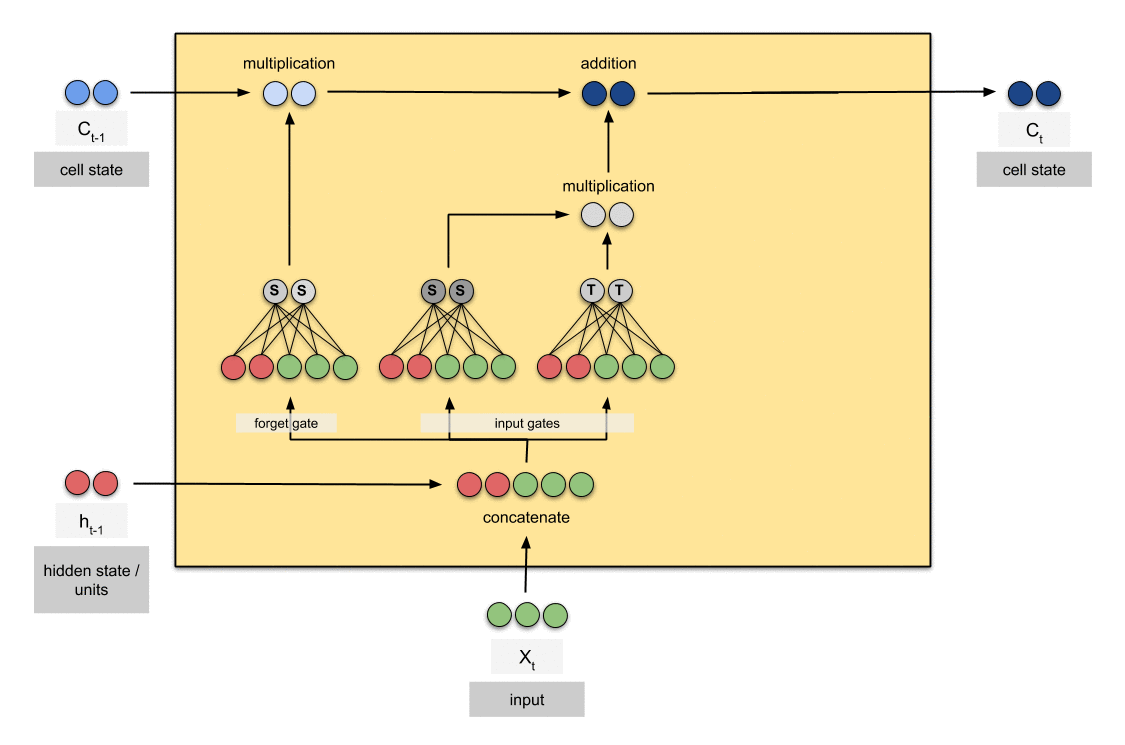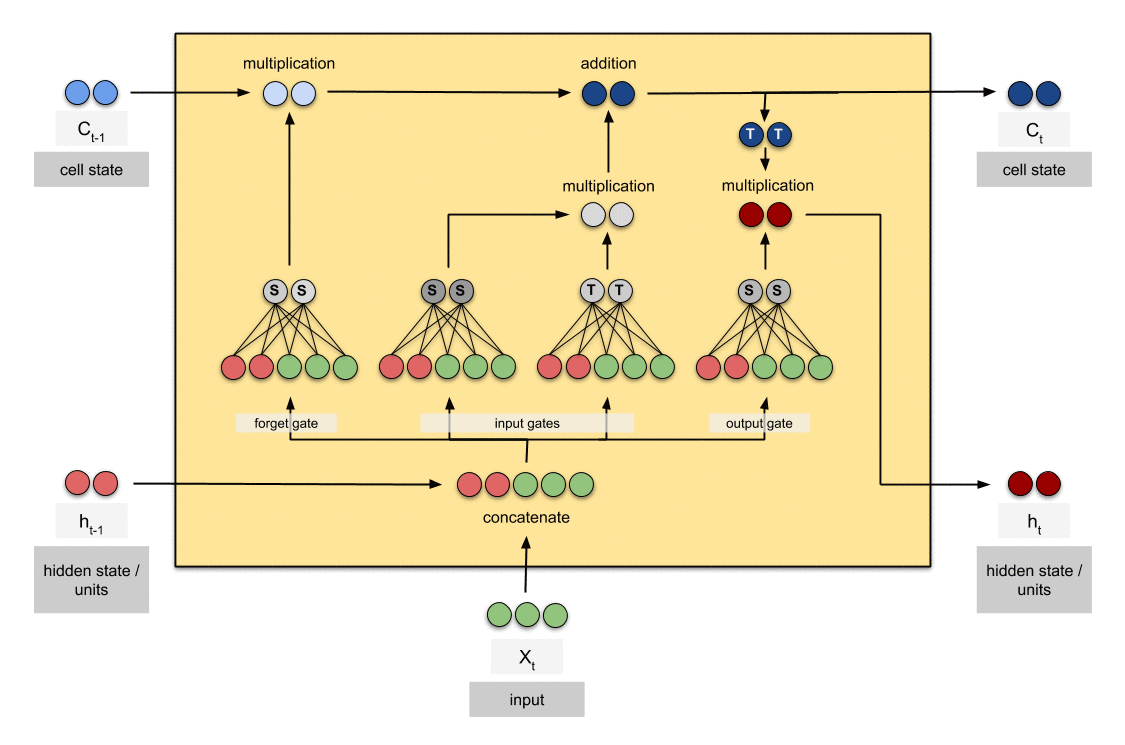
一種特殊的RNN,能夠學習長期依賴。
LSTM在很長一段時間內具有記憶資訊的特性。

LSTM had a three step Process:
看下圖說每個LSTM模塊將有3個閥,命名為忘記閥(Forget gate),輸入閥(Input gate),輸出閥(Output gate)。
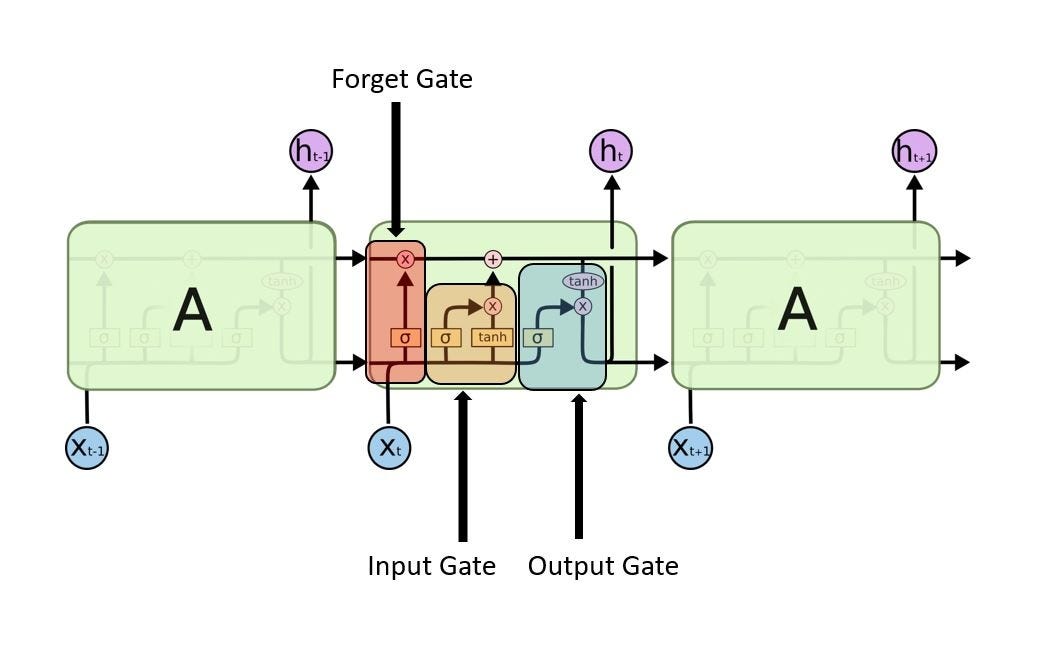
Forget Gate:
決定你應該記住多少過去。
此閥決定單元格中在特定時間標記中該省略哪些資訊。 它由sigmoid函數決定。 它查看先前的狀態(ht-1)和內容輸入(Xt),並為單元狀態Ct-1中的每個數字輸出0(omit this)和1(keep this)之間的數字。

EX:讓我們說ht-1→Roufa和Manoj在籃球比賽中表現出色。
Xt→Manoj非常擅長網頁設計。
(i) 忘記閥意識到在遇到第一個完全停止後,上下文中可能會有變化。
(ii) 與Current Input Xt比較。
(iii) 重要的是要知道下一句話,談論Manoj。 所以關於Roufa的信息被省略了。
Update Gate/input gate:
決定將此單位被添加多少數量到當前狀態。
Decides how much of this unit is added to the current state.

Sigmoid函數決定允許通過0,1的值。 和tanh函數給予通過的值權重,決定它們的重要性程度從-1到1。
EX:Manoj擅長網絡設計,昨天他告訴我他是大學的頂級人物。
(i) 輸入閥分析重要資訊。
(ii) Manoj擅長網頁設計,他是大學的頂級學生很重要。
(iii) 昨天他告訴我這不重要,因此被遺忘了。
Output Gate:
決定當前單元格的哪個部分輸出。

Sigmoid函數決定允許通過0,1的值。 和tanh函數給予通過的值權重,決定它們的重要性程度從-1到1並乘以Sigmoid的輸出。
EX:Manoj擅長網絡設計,他是大學的頂級學生,所以優秀學生_______________被授予大學金牌得主。
空的破折號可能有很多選擇。 最後的閥用Manoj取代。
LSTM的部落格與很好的可視化在這裡。
參考
https://medium.com/@purnasaigudikandula/recurrent-neural-networks-and-lstm-explained-7f51c7f6bbb9?fbclid=IwAR1IWaesvLofzWS5o0REhPVDWJwocpd7Hmzr_cIOSVHo5EqgjsuCAqj-5CY
沒有留言:
張貼留言