Problem definition
科學數據集通常僅限於一種數據,例如文本,圖像或數字數據(numerical data)。 這很有意義,因為目標是將新模型和方法進行比較。 無論如何,通常macchine learning模型組合了多個單一數據源,因此處理不同類型的數據。 為了利用端到端學習神經網絡,我們需要在神經網絡內部組合這些不同的特徵空間,而不是手動堆疊模型。
假設我們想要解決文本分類問題,並且我們的語料庫中的每個文檔都有其他meta data。 在簡單的方法中,我們的文檔由一個詞袋(bag of words)表示,我們可以將我們的meta data添加到BoW向量中,我們就完成了。 但是當使用單詞嵌入時,它有點複雜。
Special Embeddings
最簡單的解決方案是將我們的meta data添加為額外的特殊embeddings。 在這種情況下,我們需要將數據轉換為分類特徵,因為我們的embeddings可以存在或不存在。 如果我們透過附加數值特徵來增加詞彙量大小並將它們視為附加單詞,則此方法有效。
範例:我們的字典是100個單詞,我們有10個附加特徵。 在這種情況下,我們在字典中添加10個單詞。 embeddings序列現在總是以meta data特徵開始,因此我們必須將序列長度增加10。這10個特殊embeddings中的每一個都代表了meta data的特徵。
這種解決方案有幾個缺點。 我們只有分類特徵,而不是連續值,更重要的是我們的嵌入空間混合了自然語言處理和元資料。
Multiple input models
更好的是一個模型,它可以處理連續數據,只是作為具有nlp功能和元數據的分類器。 這可以通過keras中的多個輸入來實現。 例:
Much better is a model, which can handle continuous data and just works as a classifier with nlp features and meta data. This is possible with multiple inputs in keras. Example:
nlp_input = Input(shape=(seq_length,), name='nlp_input')
meta_input = Input(shape=(10,), name='meta_input')
emb = Embedding(output_dim=embedding_size, input_dim=100, input_length=seq_length)(nlp_input)
nlp_out = Bidirectional(LSTM(128, dropout=0.3, recurrent_dropout=0.3, kernel_regularizer=regularizers.l2(0.01)))(emb)
x = concatenate([nlp_out, meta_input])
x = Dense(classifier_neurons, activation='relu')(x)
x = Dense(1, activation='sigmoid')(x)
model = Model(inputs=[nlp_input , meta_input], outputs=[x])我們使用雙向LSTM模型並將其輸出與metadata相結合。 因此,我們定義了兩個輸入層,並在單獨的模型中處理它們(nlp_input和meta_input)。 我們的自然語言處理數據通過embedding轉換和LSTM層。 meta data就按照原本方式使用,所以我們可以將它與lstm輸出(nlp_out)連接起來。 現在將該組合的向量在dense layer被分類,最後將sigmoid分類為輸出神經元。
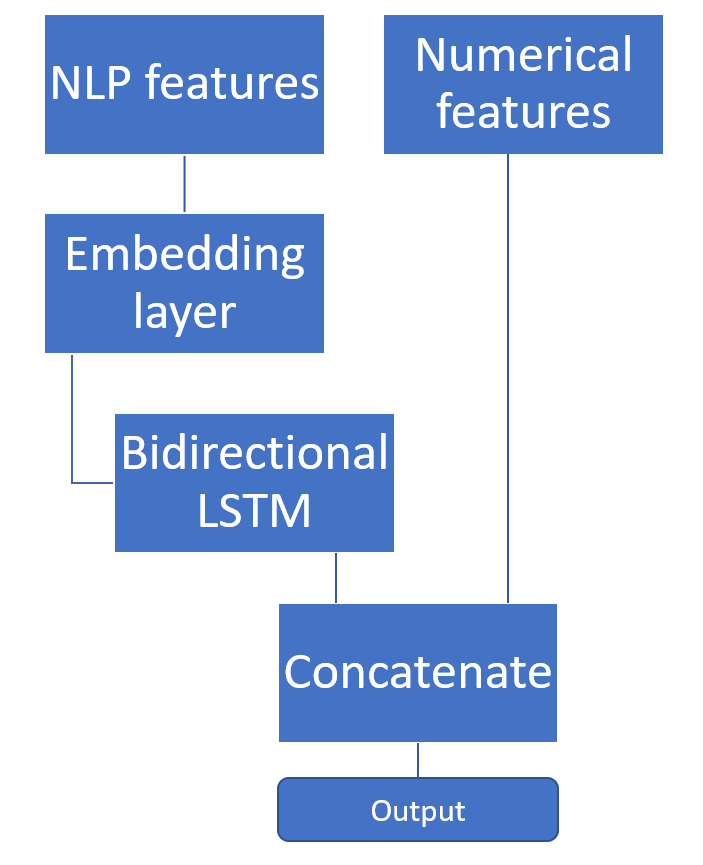
該概念可用於任何其他領域,其中來自RNN的序列數據與非序列數據混合。 LSTM的輸出表示中間空間(intermidiate space)中的序列。 這意味著LSTM的輸出也是一種特殊的embedding。
參考
http://digital-thinking.de/deep-learning-combining-numerical-and-text-features-in-deep-neural-networks/
沒有留言:
張貼留言