查看Stanford Convolutional Neural networks for visual recognition的課程1,了解視覺識別課程,了解神經網絡背後的歷史。
Why Convolutional Neural Networks?
我們知道神經網絡擅長圖像識別(Image Recognition)。 現在,如果你考慮這個圖像識別工作,這甚至可以通過神經網絡實現,但問題是,如果圖像是大像素,那麼神經網絡的參數會增加。 這使得神經網絡變慢並消耗大量計算能力。
例如:如果您處理64 * 64 * 3大小的圖像,那麼您將獲得12288輸入參數。 但如果圖像是1000 * 1000 * 3的高解析度,那麼它有300萬個輸入參數要處理。 這需要大量的時間和計算能力。
點擊這裡查看更多相關資訊。
Applications:
Object detection:

Edge detection:

Semantic segmentation:

Image caption:

Question &Answering:

Obeject tracking
Video classfication
style transfer
……….
What are Convolutional Neural Networks?
與神經網絡不同,卷積神經網絡攝取和處理圖像作為張量,張量是具有附加維度的數字矩陣。
計算機看到的圖像與人類不同。 他們將圖像視為像素。
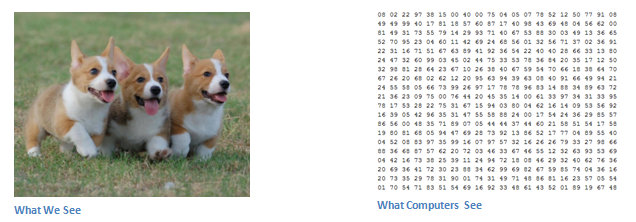
假設我們有JPG格式的彩色圖像,其大小為480 x 480.代表性陣列為480 x 480 x 3(通道= RGB)。 這些數字中的每一個都給出0到255之間的值,該值描述了該點的像素強度。 這些數字雖然在我們執行圖像分類時對我們毫無意義,但卻是計算機唯一可用的輸入。
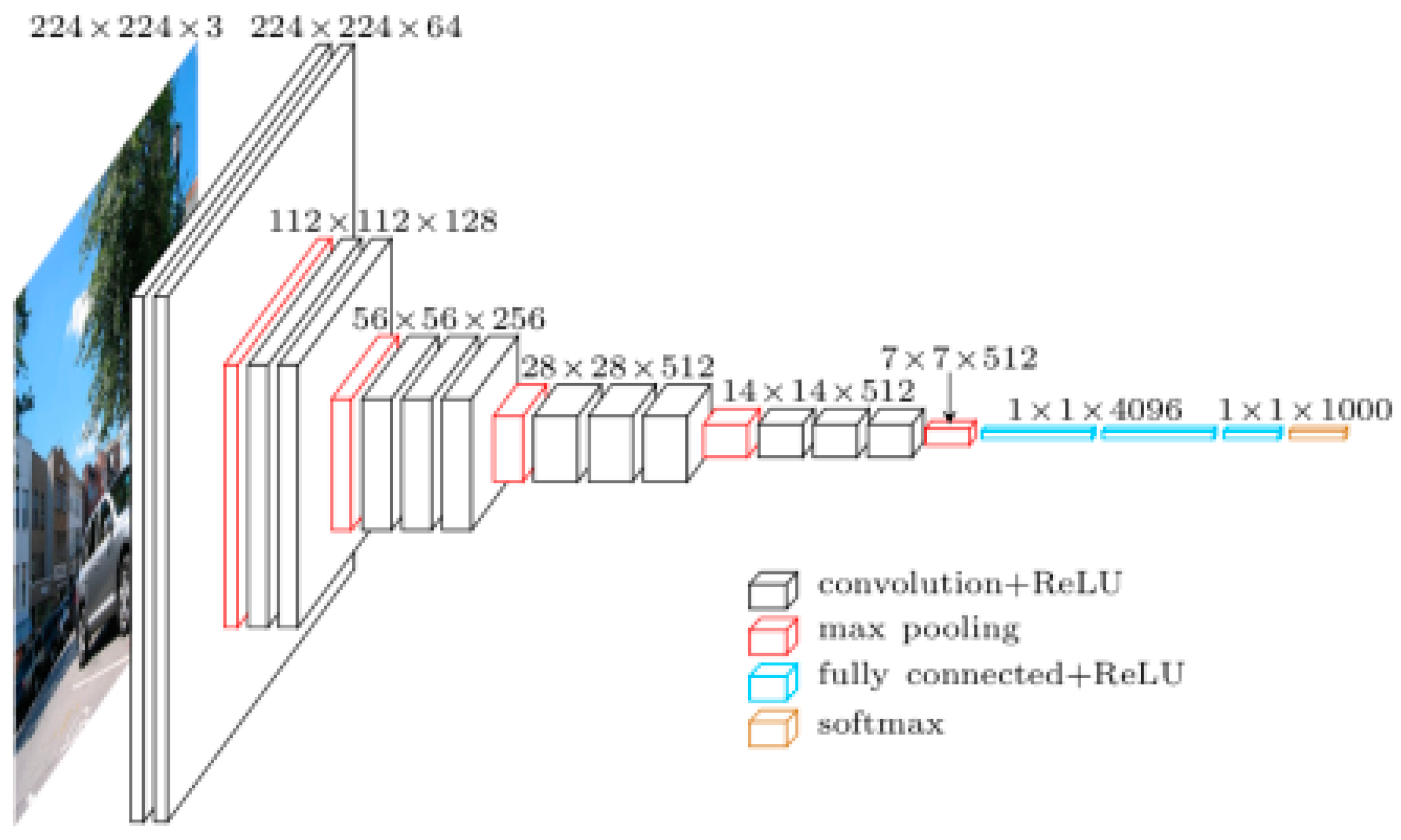
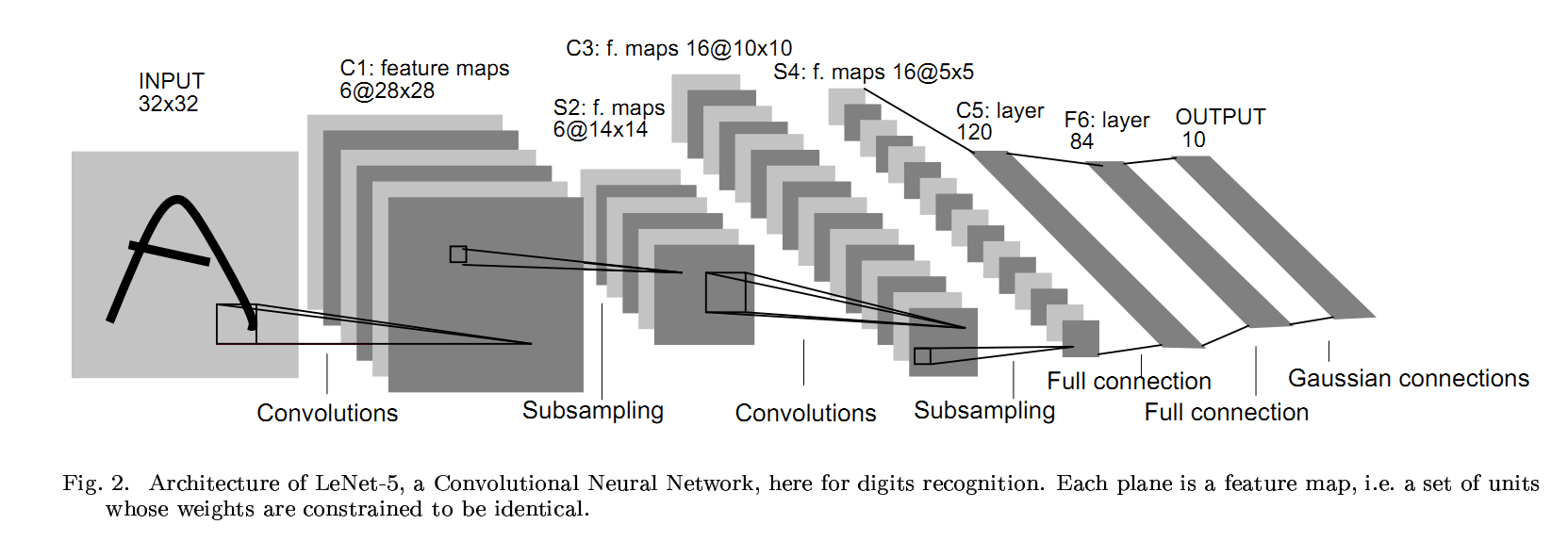
卷積神經網絡有兩個主要組成部分。
1.Feature learning:您可以在此處查看卷積,ReLU,池化層(Pooling layer)。 將提取此特徵學習步驟中的邊緣,陰影,線條,曲線。
2.classification:您可以看到完全連接(Fully Connected)層。 它們將為圖像上的對象分配概率,即演算法預測的概率。
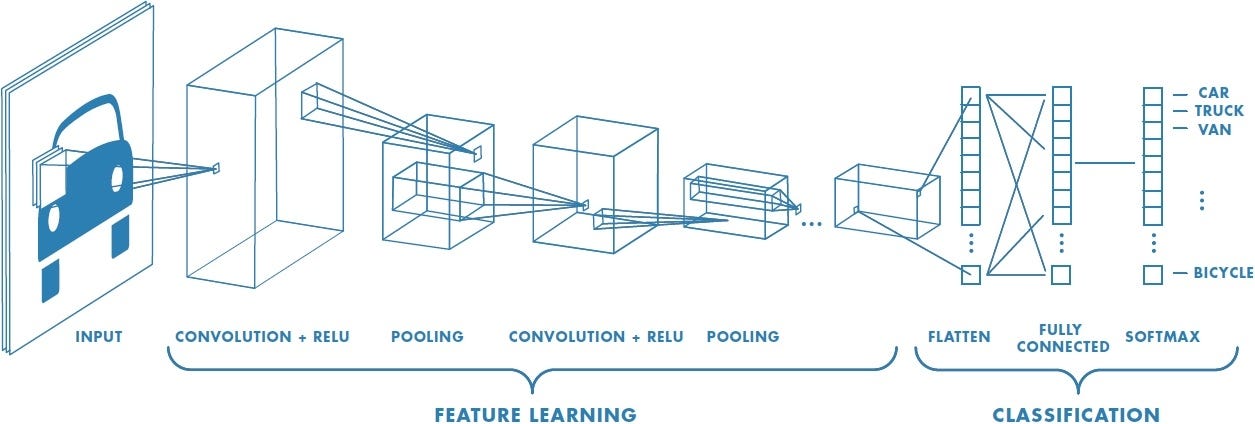
Phase-1: Feature learning
Convolution :
input image:
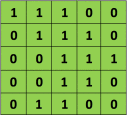
如上所述,每個圖像都可以被視為像素值矩陣。 考慮一個5 x 5圖像,其像素值僅為0和1(請注意,對於灰度圖像,像素值範圍為0到255,下面的綠色矩陣是像素值僅為0和1的特殊情況)
Filter:
此輸入圖像乘以過濾鏡(filter)以獲得Convolved layer。 這些過濾鏡的形狀和值不同,以獲得不同的特徵,如邊緣,曲線,線條。 此過濾器有時稱為內核(Kernel),特徵(Feature)檢測器。

讓我們考慮使用3 * 3過濾鏡從輸入圖像中提取某些特徵,這些特徵是上面輸入圖像的像素值。

filter/kernel
Convolved layer:
輸入圖像的每個像素中的每個值乘以相應的值和過濾鏡的像素,這裡給出了卷積層。 這個Convlayer在這裡有時被稱為卷積特徵(Convolutional Feature),特徵映射(Feature map),過濾器映射(Filter map)。
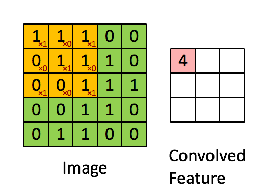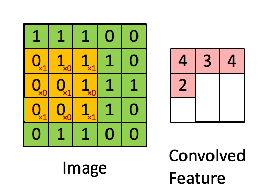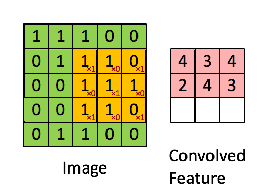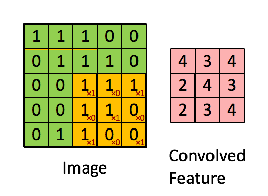
Convolved feature/feature map extracted by applying the filter/kernel on input image
Convolved功能的結果取決於三個參數。 我們需要在執行卷積之前定義。
Depth: 在上面的輸入圖像中,我們只考慮depth =1的圖像,但大多數輸入將是depth =3,其為3個通道,如紅色,綠色,藍色。
Stride: Stride是我們在輸入矩陣上滑動過濾鏡矩陣的像素數。 當Stride為1時,我們一次移動濾波器一個像素。 當Stride為2時,當我們滑動它們時,濾波器一次跳躍2個像素。 更大的Stride將產生更小的特徵映射。
Padding: 就像您為圖像添加了多少像素, 大多數填充將是1,如下圖所示,圖像用4 * 4像素填充1。
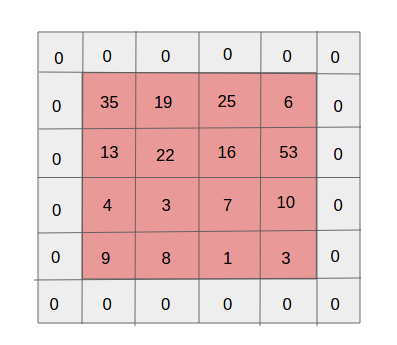
input image of 4*4 pixel with padding of 0
Summary
總結一下,Conv層:
1.接受尺寸為W1×H1×D1的體積
2.需要四個超參數:
(i) 過濾器數量K
(ii) 他們的過濾器尺寸F
(iii) 步幅S
(iv) 零填充量P
3.產生體積大小W2×H2×D2,其中:
(i) W2 = (W1-F+2P)/S+1
(ii) H2 = (H1-F+2P)/S+1(即寬度和高度通過對稱計算)
(iii) D2 = K
ReLU(Rectified Linear Unit):introduces non-linearity
每次卷積操作後都會使用ReLU。 Relu是非線性操作
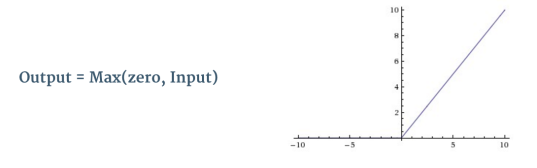
ReLU是element wise操作(按像素應用)並將要素圖中的所有負像素值替換為零。 ReLU的目的是在我們的ConvNet中引入非線性,因為我們希望我們的ConvNet學習的大多數真實數據都是非線性的(卷積是線性操作 - 元素明智的矩陣乘法和加法,所以藉由導入像ReLU這樣的非線性函數來解釋非線性)。

Pooling layer:
在此階段,為了保留重要資訊而減少了convlayer或feature map的維度。 有時,這種空間pooling也稱為Downsampling或subsampling。 此池化層(pooling layer)可以是最大池(Max pooling),平均池(Avg pooling),總和池(sum pooling)。 大多數情況下,我們看到Max pooling使用最多。

接受體積為W1×H1×D1的體積
1.需要兩個超參數:
(i) 他們的空間範圍F
(ii) 步幅S
2.產生尺寸為W2×H2×D2的體積,其中:
(i) W2 = (W1-F)/S+1
(ii) H2 = (H1-F)/S+1
(iii) D2 = D1
Phase-2:Classification
Fully connected layer:
完全連接層是傳統的多層感知器,在輸出層使用softmax激活函數。術語“完全連接”意味著前一層中的每個神經元都連接到下一層的每個神經元。
卷積和池化層的輸出代表輸入圖像的high-level特徵。完全連接層的目的是使用這些特徵根據訓練數據集將輸入圖像分類為各式各樣的種類。
在完全連接層的輸出層中使用Softmax作為的激活函數可以確保輸出概率之總和為1。Softmax函數採用任意real-valued分數的向量,並將其壓縮為0到1之間的值的向量,其總和為1。
在上圖中,使用softmax到完全連接的層會產生出了汽車,卡車和自行車等級的概率值。
參考
https://medium.com/@purnasaigudikandula/a-beginner-intro-to-convolutional-neural-networks-684c5620c2ce
沒有留言:
張貼留言