最重要的是,我們將在FrançoisChollet的“使用Python深度學習”書中複製一些工作,以便了解我們的層結構如何根據每個中間激活的可視化處理數據,其中包括顯示由網絡中的捲積和池化層輸出的feature maps。
這意味著我們將可視化每個激活層的結果。
我們將快速倒ㄌ,因為我們沒有專注於使用Keras解釋CNN的細節。
我們先導入所有必需的函式庫:
%matplotlib inline
import glob import matplotlib from matplotlib import pyplot as plt import matplotlib.image as mpimg import numpy as np import imageio as im from keras import models from keras.models import Sequential from keras.layers import Conv2D from keras.layers import MaxPooling2D from keras.layers import Flatten from keras.layers import Dense from keras.layers import Dropout from keras.preprocessing import image from keras.preprocessing.image import ImageDataGenerator from keras.callbacks import ModelCheckpoint
這些是我們的訓練圖像:
Circles
images = []
for img_path in glob.glob('training_set/circles/*.png'):
images.append(mpimg.imread(img_path))
plt.figure(figsize=(20,10))
columns = 5
for i, image in enumerate(images):
plt.subplot(len(images) / columns + 1, columns, i + 1)
plt.imshow(image)
正方形
(代碼與上面幾乎相同,請在此處查看完整代碼)
Triangles
圖像形狀在RGB比例中為28像素乘28像素(儘管它們僅可以說是黑色和白色)。
現在讓我們繼續我們的捲積神經網絡構造。 通常,我們使用Sequential()啟動模型:
# Initialising the CNN classifier = Sequential()
我們指定卷積層並將MaxPooling添加到降低取樣和Dropout以防止過度擬合。 我們使用Flatten並以3個單位的密集層結束,每個類別(circle [0],square [1],triangle [1])。 我們將softmax指定為我們的最後一個激活函數,建議用於多類分類。
# Step 1 - Convolution classifier.add(Conv2D(32, (3, 3), padding='same', input_shape = (28, 28, 3), activation = 'relu')) classifier.add(Conv2D(32, (3, 3), activation='relu')) classifier.add(MaxPooling2D(pool_size=(2, 2))) classifier.add(Dropout(0.5)) # antes era 0.25
# Adding a second convolutional layer classifier.add(Conv2D(64, (3, 3), padding='same', activation = 'relu')) classifier.add(Conv2D(64, (3, 3), activation='relu')) classifier.add(MaxPooling2D(pool_size=(2, 2))) classifier.add(Dropout(0.5)) # antes era 0.25
# Adding a third convolutional layer classifier.add(Conv2D(64, (3, 3), padding='same', activation = 'relu')) classifier.add(Conv2D(64, (3, 3), activation='relu')) classifier.add(MaxPooling2D(pool_size=(2, 2))) classifier.add(Dropout(0.5)) # antes era 0.25
# Step 3 - Flattening classifier.add(Flatten())
# Step 4 - Full connection classifier.add(Dense(units = 512, activation = 'relu')) classifier.add(Dropout(0.5)) classifier.add(Dense(units = 3, activation = 'softmax'))
對於這種類型的圖像,一旦我們看一下這些feature maps就會很明顯了解我可能正在構建一個過於複雜的結構,但是它可以幫助我準確地展示每個層的內容。不過我確信我們可以用更少的層和更少的複雜性獲得相同或更好的結果。
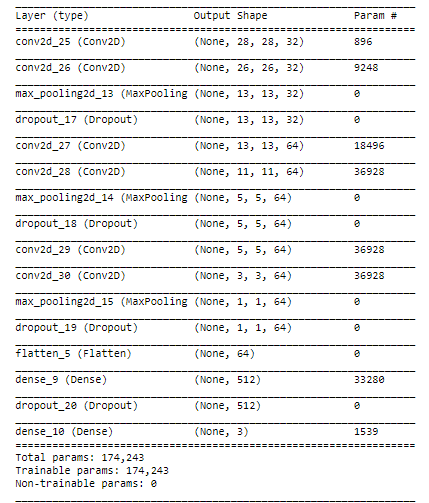
來看看我們的模型摘要:
classifier.summary()
我們使用rmsprop作為我們的優化器編譯模型,使用categorical_crossentropy作為我們的損失函數,並將accuracy指定為metric:
# Compiling the CNN
classifier.compile(optimizer = 'rmsprop',
loss = 'categorical_crossentropy',
metrics = ['accuracy'])
此時我們需要將圖片轉換為模型可以接受的形狀。 為此,我們使用ImageDataGenerator。 我們啟動它並使用.flow_from_directory提供圖像。 工作目錄中有兩個主文件夾,名為training_set和test_set。 每個子文件夾都有3個子文件夾,分別稱為circles,squares和triangles。 我已經將每個形狀的70個圖像發送到training_set,將30個圖像發送到test_set。
train_datagen = ImageDataGenerator(rescale = 1./255) test_datagen = ImageDataGenerator(rescale = 1./255)
training_set = train_datagen.flow_from_directory('training_set',target_size = (28,28), batch_size = 16, class_mode = 'categorical')
test_set = test_datagen.flow_from_directory('test_set',
target_size = (28, 28), batch_size = 16, class_mode = 'categorical')
該模型將訓練30個epochs,但我們將使用ModelCheckpoint來存儲表現最佳epoch的權重。 我們將val_acc指定為用於定義最佳模型的metric。 這意味著我們將保持在測試集上的準確度方面得分最高的epoch的權重。
checkpointer = ModelCheckpoint(filepath="best_weights.hdf5",
monitor = 'val_acc',
verbose=1,
save_best_only=True)
Training the model
現在是時候訓練模型了,這裡我們包括對checkpointer的callback
history = classifier.fit_generator(training_set,
steps_per_epoch = 100,
epochs = 20,
callbacks=[checkpointer],
validation_data = test_set,
validation_steps = 50)
該模型訓練了20個epochs,並在epochs 10達到了它的最佳表現。我們得到以下資訊:
`Epoch 00010:val_acc從0.93333提高到0.95556,將模型保存到best_weights.hdf5`
在那之後,模型沒有針對下一個epochs進行改進,因此epochs 10的權重是被存儲的 - 這意味著我們現在有一個hdf5文件存儲該特定epoch的權重,其中測試集的準確度為95.6%
我們將確保我們的分類器加載了最佳權重
classifier.load_weights('best_weights.hdf5')
最後,讓我們保存最終模型以供日後使用:
classifier.save('shapes_cnn.h5')
Displaying curves of loss and accuracy during training
現在讓我們來看看我們的模型在30個epochs中的表現:
acc = history.history['acc'] val_acc = history.history['val_acc'] loss = history.history['loss'] val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
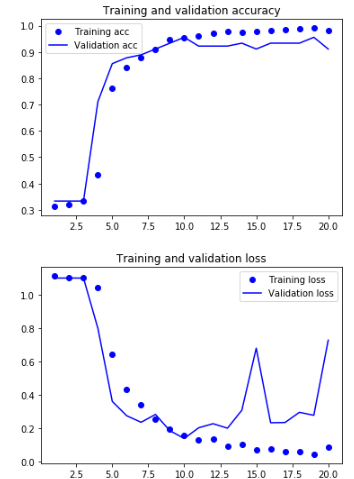
我們可以看到,在第10個epoch之後,模型開始過度擬合。 無論如何,我們保留了具有最佳性能的epoch結果。
Classes
讓我們現在闡明分配給我們每個圖片集的類別編號,因為這就是模型將如何產生它的預測:
circles:0
squres:1
triangles:2
Predicting the class of unseen images
藉由我們的模型訓練和存儲,我們可以從我們的測試集中加載一個簡單的未見過的圖像,看看它是如何分類的:
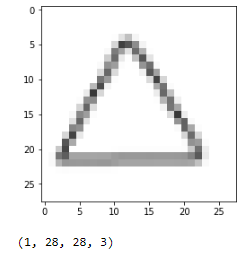
img_path = 'test_set/triangles/drawing(2).png'
img = image.load_img(img_path, target_size=(28, 28)) img_tensor = image.img_to_array(img) img_tensor = np.expand_dims(img_tensor, axis=0) img_tensor /= 255.
plt.imshow(img_tensor[0]) plt.show()
print(img_tensor.shape)
# predicting images x = image.img_to_array(img) x = np.expand_dims(x, axis=0)
images = np.vstack([x])
classes = classifier.predict_classes(images, batch_size=10)
print("Predicted class is:",classes)
> Predicted class is: [2]
預測是類別[2],它是一個三角形。
到現在為止還挺好。 我們現在進入本文最重要的部分
Visualizing intermediate activations
引用FrançoisChollet的書“DEEP LEARNING with Python”(我將在本節中引用他很多):
中間激活“有助於理解連續的convnet層如何轉換其輸入,以及首先了解各個convnet濾波器的含義。”
“通過網絡學習所獲得的表徵(representations)非常適合可視化,這在很大程度上是因為它們是視覺概念的表現形式。可視化中間激活包括在給定特定輸入的情況下顯示由網絡中的各種卷積和池化層輸出的feature maps(層的輸出通常稱為其激活,激活函數的輸出)。這給出瞭如何藉由網絡學習將輸入分解成不同過濾器。每個通道編碼相對獨立的特徵,因此可視化這些feature maps的正確方法是將每個通道的內容獨立繪製為2D圖像。
接下來,我們將得到一個輸入圖像 - 一個三角形的圖片,而不是網絡訓練過的圖像的一部分。
“為了提取我們想要查看的feature maps,我們將創建一個Keras模型,該模型將批量圖像作為輸入,並輸出所有捲積和池化層的激活。為此,我們將使用Keras類別Model。使用兩個參數來實例化模型:輸入張量(或輸入張量list)和輸出張量(或輸出張量list)。結果類別是Keras模型,就像Sequential模型一樣,將指定的輸入映射到指定的輸出。 Model類別與眾不同之處在於,與Sequential不同,它允許具有多個輸出的模型。“
Instantiating a model from an input tensor and a list of output tensors
layer_outputs = [layer.output for layer in classifier.layers[:12]] # Extracts the outputs of the top 12 layers
activation_model = models.Model(inputs=classifier.input, outputs=layer_outputs) # Creates a model that will return these outputs, given the model input
當輸入圖像輸入時,此模型返回原始模型中圖層激活的值。
Running the model in predict mode
activations = activation_model.predict(img_tensor) # Returns a list of five Numpy arrays: one array per layer activation
For instance, this is the activation of the first convolution layer for the image input:
first_layer_activation = activations[0] print(first_layer_activation.shape)
(1, 28, 28, 32)
它是一個28×28的feature map,有32個通道。 讓我們嘗試繪製原始模型第一層激活的第四個通道
plt.matshow(first_layer_activation[0, :, :, 4], cmap='viridis')
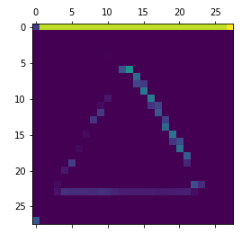
甚至在我們嘗試解釋這種激活之前,讓我們在每一層上繪製同一圖像的所有激活
Visualizing every channel in every intermediate activation
可在此處找到此部分的完整代碼
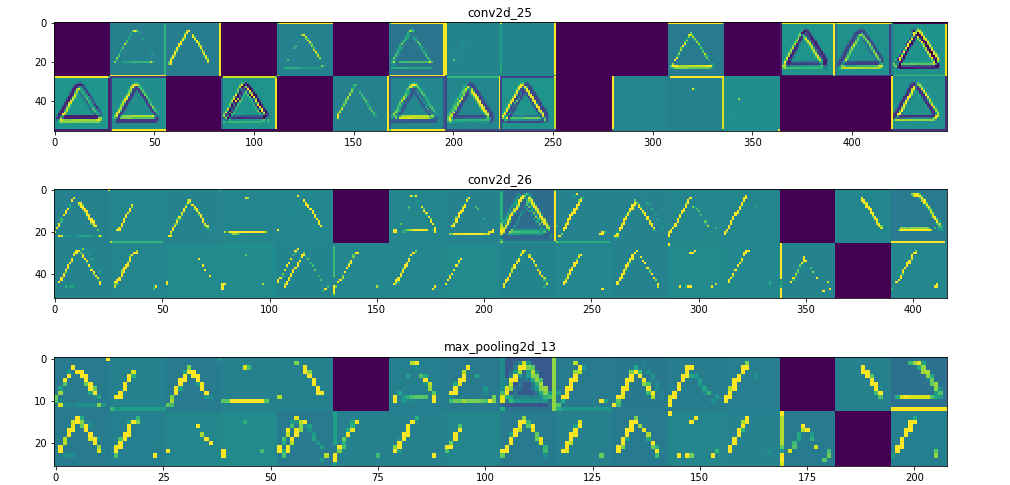
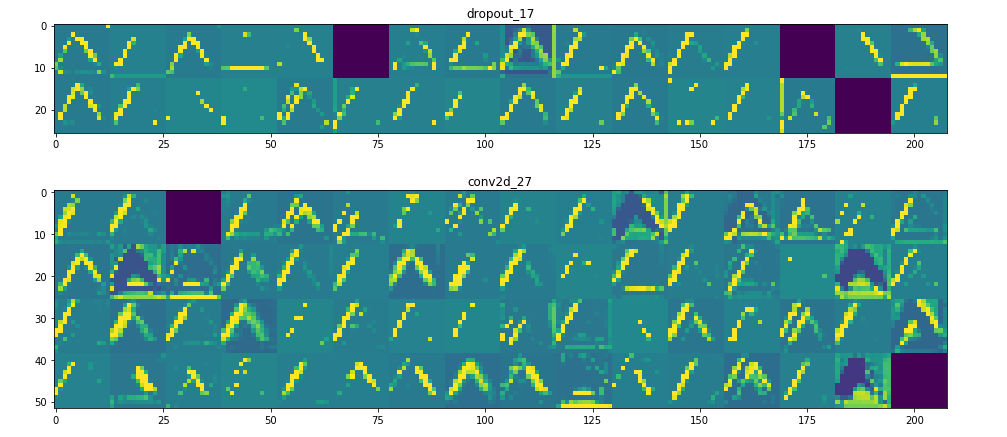
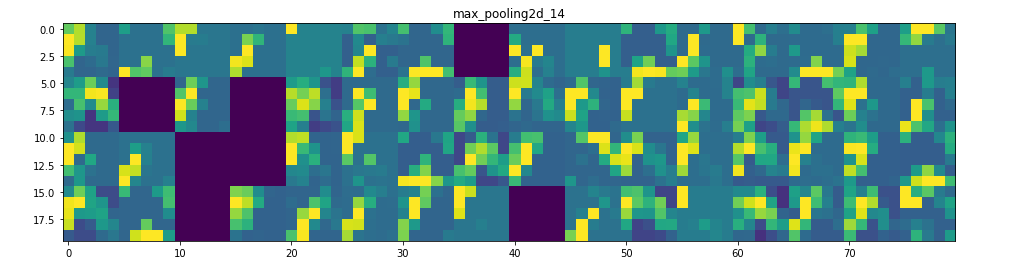
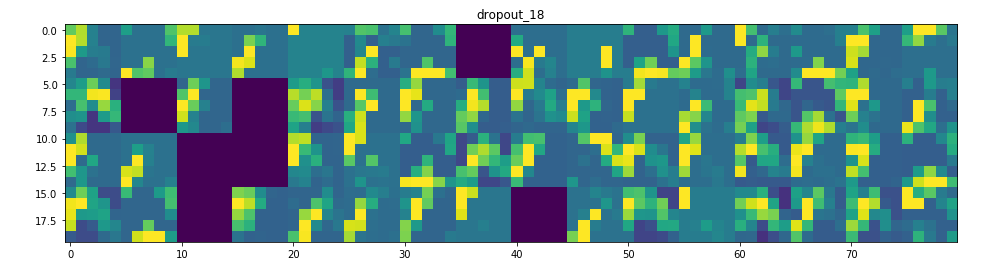
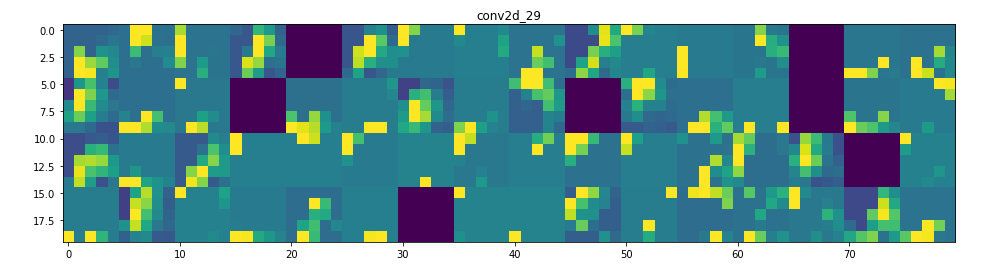
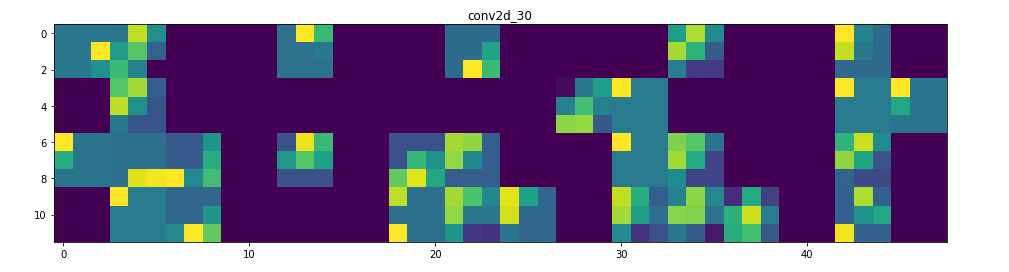
所以在這裡!讓我們試著解釋發生了什麼:
1. 第一層可以保留triangle的完整形狀,儘管有幾個過濾器未被激活並留空。在那個階段,激活幾乎保留了初始圖片中的所有資訊。
2. 隨著我們在各個層面的深入,激活變得越來越抽象,在視覺上也不那麼容易理解。他們開始編碼更高級別的概念,如單邊框,角落和角度。較高的presentations帶來關於圖像的視覺內容的資訊越來越少,並且越來越多的資訊與圖像的類別相關。
3. 如上所述,模型結構過於復雜,我們可以看到我們的最後一層實際上根本沒有激活,在那一點上沒有什麼需要學習的。
這就是它!我們已經可視化卷積神經網絡如何在一些基本圖形中找到模式以及它如何將資訊從一個層傳遞到另一個層。
參考
https://towardsdatascience.com/visualizing-intermediate-activation-in-convolutional-neural-networks-with-keras-260b36d60d0?fbclid=IwAR2GqxH-5EwqPycPVy-IhliMQKesA3gJMwJltWishQuv8c9rxzCIKPIa5sQ
沒有留言:
張貼留言