許多文章都集中在二維卷積神經網絡上。 它們特別用於圖像識別問題。 1D CNN在某種程度上被隱匿,例如, 用於自然語言處理(NLP)。 很少有文章提供關於如何構建1D CNN的逐步指令解釋,以及您可能面臨的其他機器學習問題。 本文試圖彌合這一差距。
When to Apply a 1D CNN?
CNN非常適合識別數據中的簡單模式,然後用在更高階層中形成更複雜的模式。 當您希望從整個數據集較短(固定長度)段落中獲得有趣的特徵並且該段落中的特徵的位置不具有高度相關性時,1D CNN是非常有效的。
這很適用於傳感器數據的時間序列分析(例如陀螺儀或加速度計數據)。 它還適用於在固定長度週期內(例如音頻信號)分析任何類型的信號數據。 另一個應用是NLP(雖然這裡LSTM網絡更有前景,因為鄰近的單詞在訓練模式下可能並不是良好的指標)。
What is the Difference Between a 1D CNN and a 2D CNN?
無論是1D,2D還是3D。 關鍵區別在於輸入數據的維度以及特徵檢測器(或過濾器)如何在數據中滑動:
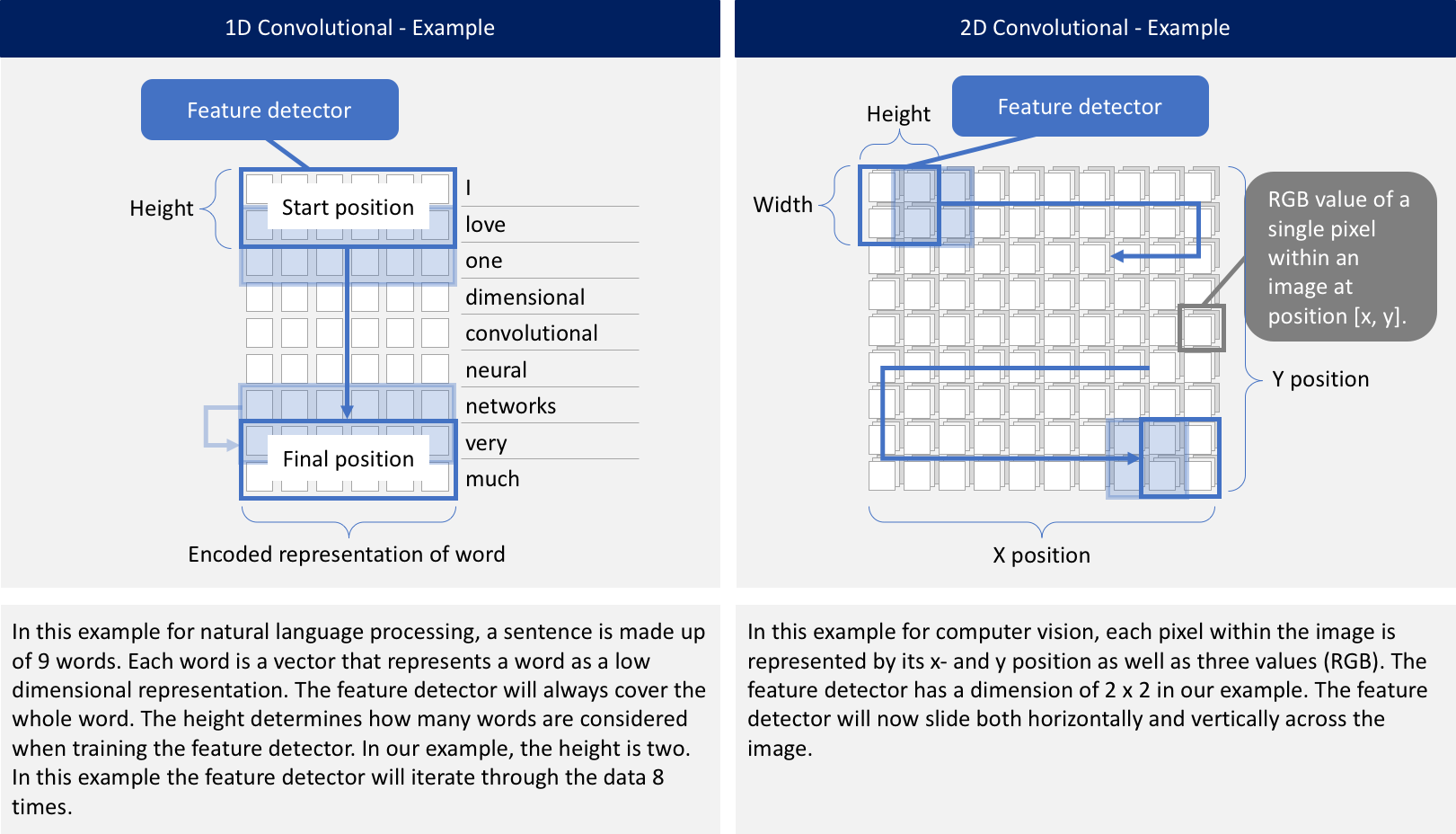
Problem Statement
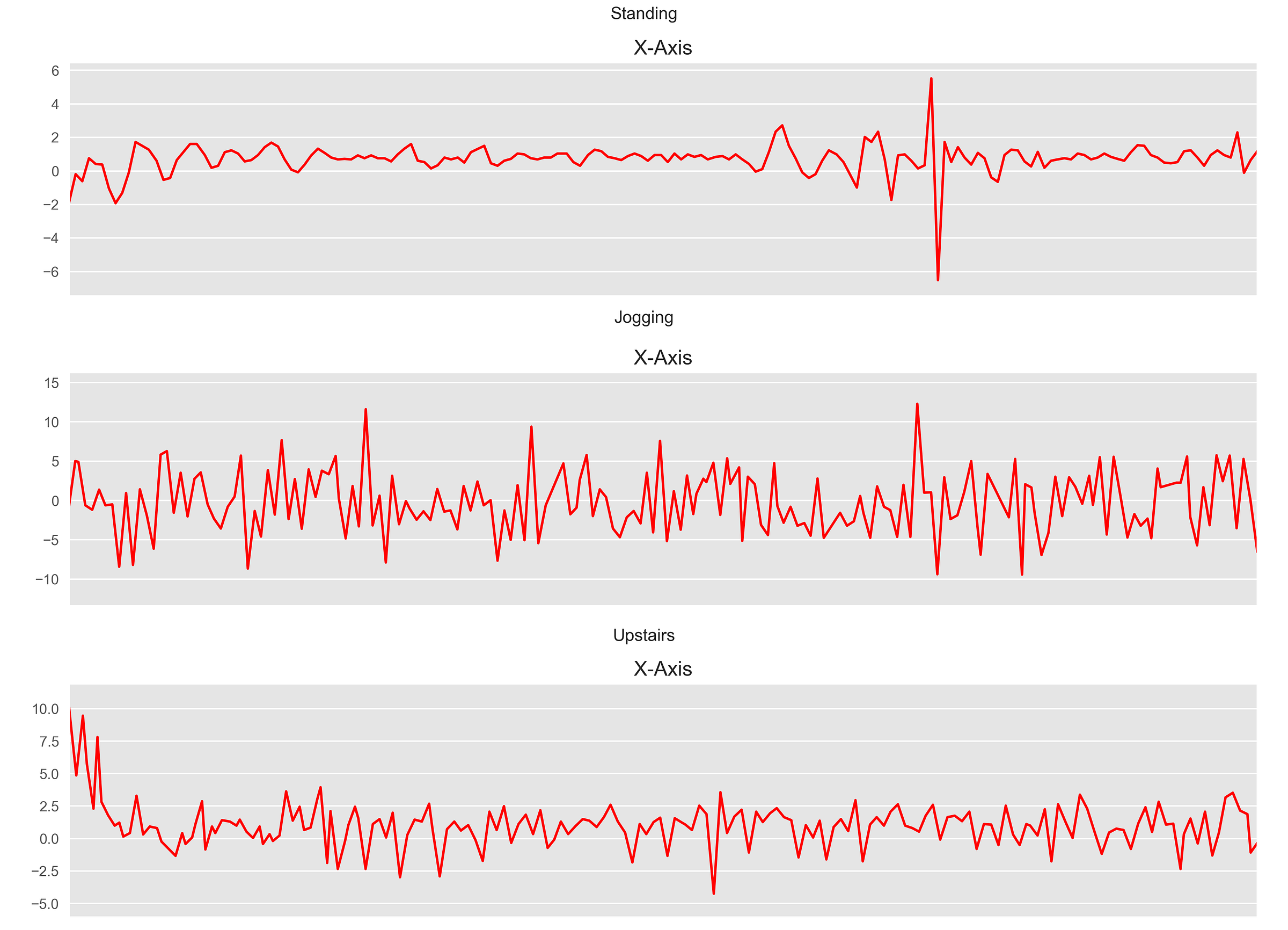
在本文中,我們將重點關注來自用戶腰部攜帶的智能手機其時間切片加速計傳感器數據。 基於x,y和z軸的加速度計數據,1D CNN應預測用戶正在執行的活動類型(例如“行走”,“慢跑”或“站立”)。 您可以在此處和此處的其他兩篇文章中找到更多資訊。
https://towardsdatascience.com/human-activity-recognition-har-tutorial-with-keras-and-core-ml-part-1-8c05e365dfa0
https://towardsdatascience.com/human-activity-recognition-har-tutorial-with-keras-and-core-ml-part-2-857104583d94
對於各種活動,數據的每個時間間隔看起來都類似於此。
How to Construct a 1D CNN in Python?
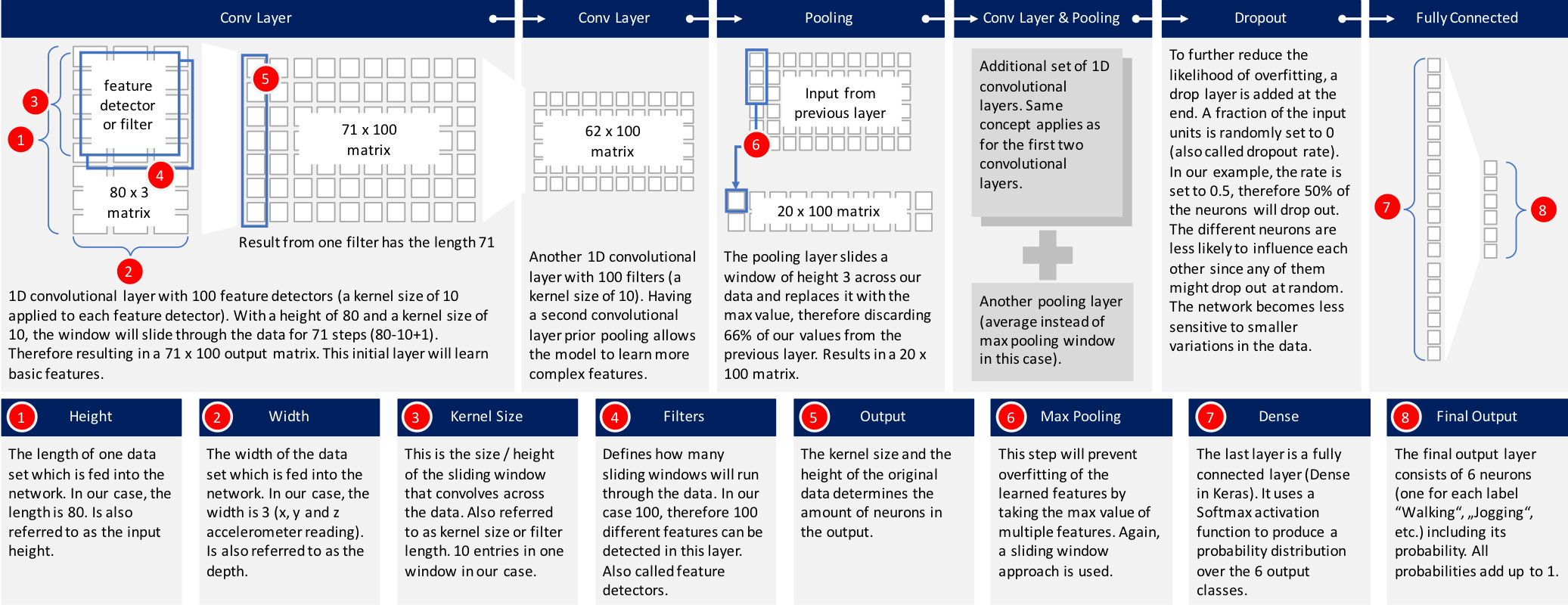
有許多標準CNN模組可供選擇。 我選擇了Keras網站上描述的其中一個模型並對其進行了微調,以吻合上述問題。 下圖提供了高級概述的構建模型。 將進一步解釋每一層。
但是,讓我們首先看一下Python代碼,以構建這個模型:
model_m = Sequential() model_m.add(Reshape((TIME_PERIODS, num_sensors), input_shape=(input_shape,))) model_m.add(Conv1D(100, 10, activation='relu', input_shape=(TIME_PERIODS, num_sensors))) model_m.add(Conv1D(100, 10, activation='relu')) model_m.add(MaxPooling1D(3)) model_m.add(Conv1D(160, 10, activation='relu')) model_m.add(Conv1D(160, 10, activation='relu')) model_m.add(GlobalAveragePooling1D()) model_m.add(Dropout(0.5)) model_m.add(Dense(num_classes, activation='softmax')) print(model_m.summary())
執行此代碼將導致以下深度神經網絡:
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= reshape_45 (Reshape) (None, 80, 3) 0 _________________________________________________________________ conv1d_145 (Conv1D) (None, 71, 100) 3100 _________________________________________________________________ conv1d_146 (Conv1D) (None, 62, 100) 100100 _________________________________________________________________ max_pooling1d_39 (MaxPooling (None, 20, 100) 0 _________________________________________________________________ conv1d_147 (Conv1D) (None, 11, 160) 160160 _________________________________________________________________ conv1d_148 (Conv1D) (None, 2, 160) 256160 _________________________________________________________________ global_average_pooling1d_29 (None, 160) 0 _________________________________________________________________ dropout_29 (Dropout) (None, 160) 0 _________________________________________________________________ dense_29 (Dense) (None, 6) 966 ================================================================= Total params: 520,486 Trainable params: 520,486 Non-trainable params: 0 _________________________________________________________________ None
讓我們深入了解每一層,看看發生了什麼:
1. 輸入數據:數據已經過前處理,每個數據記錄包含80個時間片段(數據以20 Hz採樣率記錄,因此每個時間間隔覆蓋4秒的加速度計讀數)。 在每個時間間隔內,存儲x軸,y軸和z軸的三個加速度計值。 這導致80×3矩陣。 由於我通常在iOS中使用神經網絡,因此必須將數據作為長度為240的扁平化向量傳遞到神經網絡中。網絡中的第一層必須將其重新整形為80 x 3的原始形狀。
3. 第二個1D CNN層:來自第一個CNN的結果將被饋送到第二個CNN層。 我們將再次定義100個不同的過濾器,以便在此級別上進行訓練。 遵循與第一層相同的邏輯,輸出矩陣的大小為62 x 100。
4. 最大池化層:通常在CNN層之後使用池化層,以降低輸出的複雜性並防止數據過度擬合。 在我們的例子中,我們選擇了三個大小。 這意味著該層的輸出矩陣的大小僅為輸入矩陣的三分之一。
5. 第三和第四1D CNN層:遵循另一序列的1D CNN層以便學習更高階特徵。 這兩層之後的輸出矩陣是2×160矩陣。
6. 平均池化層:再一個池化層,以進一步避免過度擬合。這次不是取最大值,而是神經網絡中兩個權重的平均值。輸出矩陣的大小為1 x 160個神經元。每個特徵檢測器在該層上的神經網絡中僅剩餘一個權重。
7. Dropout層:Dropout層將隨機分配0個權重給網絡中的神經元。由於我們選擇0.5的比率,50%的神經元將獲得零權重。通過此操作,網絡對較小的數據變化做出反應變得不那麼敏感。因此,它應該進一步提高我們對未知類別新資料的準確性。該層的輸出仍然是1 x 160的神經元矩陣。
8. 具有Softmax激活的完全連接層:最後一層將高度160的向量減少到六的向量,因為我們有六個類我們想要預測(“慢跑”,“坐著”,“行走”,“站立”,“樓上樓下”)。這種減少是透過另一個矩陣乘法完成的。 Softmax用作激活函數。它強制神經網絡的所有六個輸出總和為一。因此,輸出值將代表六個類別中每個類別的概率。
Training and Testing the Neural Network
下面是用於訓練模型的Python代碼,批量大小為400,訓練和驗證分為80到20。
callbacks_list = [
keras.callbacks.ModelCheckpoint(
filepath='best_model.{epoch:02d}-{val_loss:.2f}.h5',
monitor='val_loss', save_best_only=True),
keras.callbacks.EarlyStopping(monitor='acc', patience=1)
]
model_m.compile(loss='categorical_crossentropy',
optimizer='adam', metrics=['accuracy'])
BATCH_SIZE = 400
EPOCHS = 50
history = model_m.fit(x_train,
y_train,
batch_size=BATCH_SIZE,
epochs=EPOCHS,
callbacks=callbacks_list,
validation_split=0.2,
verbose=1)
該模型對於訓練數據達到97%的準確度。
... Epoch 9/50 16694/16694 [==============================] - 16s 973us/step - loss: 0.0975 - acc: 0.9683 - val_loss: 0.7468 - val_acc: 0.8031 Epoch 10/50 16694/16694 [==============================] - 17s 989us/step - loss: 0.0917 - acc: 0.9715 - val_loss: 0.7215 - val_acc: 0.8064 Epoch 11/50 16694/16694 [==============================] - 17s 1ms/step - loss: 0.0877 - acc: 0.9716 - val_loss: 0.7233 - val_acc: 0.8040 Epoch 12/50 16694/16694 [==============================] - 17s 1ms/step - loss: 0.0659 - acc: 0.9802 - val_loss: 0.7064 - val_acc: 0.8347 Epoch 13/50 16694/16694 [==============================] - 17s 1ms/step - loss: 0.0626 - acc: 0.9799 - val_loss: 0.7219 - val_acc: 0.8107
針對測試數據運行它可以發現92%的準確率。
Accuracy on test data: 0.92
Loss on test data: 0.39
考慮到我們使用標準1D CNN模型之一,這是一個很好的數字。 我們的模型在精確度,召回率和f1-score方面也得分很高。
precision recall f1-score support
0 0.76 0.78 0.77 650 1 0.98 0.96 0.97 1990 2 0.91 0.94 0.92 452 3 0.99 0.84 0.91 370 4 0.82 0.77 0.79 725 5 0.93 0.98 0.95 2397
avg / total 0.92 0.92 0.92 6584
以下簡要回顧一下這些分數的含義:
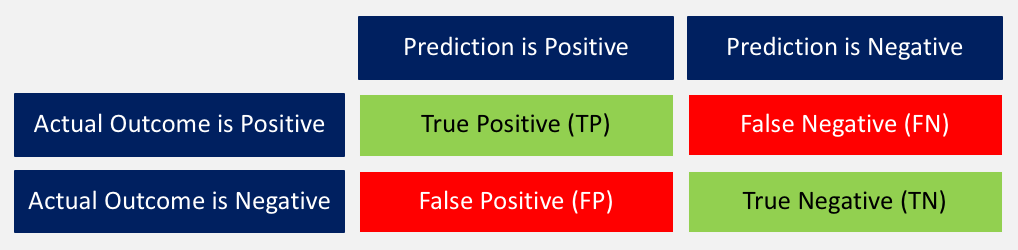
1. 準確度:正確預測結果與所有預測總和之間的比率。 ((TP + TN) / (TP + TN + FP + FN))
2. 精確度:當模型預測為positive時,是不是? 所有true positives除以所有positive預測。 (TP / (TP + FP))
3. 召回率:該模型在所有可能的positives中確定了多少positives? true positives除以所有實際positives。 (TP / (TP + FN))
4. F1-score:這是精確度和召回率的加權平均值。 (2 x召回率x精度/(召回率+精確度))
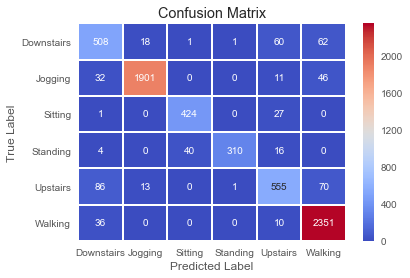
針對測試數據的相關混淆矩陣如下所示。
Summary
在本文中,您已經看到了一個範例,說明如何使用1D CNN來訓練網絡,以根據智能手機的一組給定加速度計數據預測用戶行為。 完整的Python代碼可以在github上找到。
參考
https://blog.goodaudience.com/introduction-to-1d-convolutional-neural-networks-in-keras-for-time-sequences-3a7ff801a2cf?fbclid=IwAR0B11L3DXkTHqheCSYpG1SetABlWcREFsnLQf5tSdVbFtcVkkjr9zCdngw
沒有留言:
張貼留言